C# Tesseract 강좌 : 제 2강 - 영문자 판독
Tesseract English OCR

Tesseract - OCR를 이용하여 Bitmap으로된 이미지 파일에서 영문자를 인식하여 string형식으로 반환하여 인식합니다.
Tesseract 준비
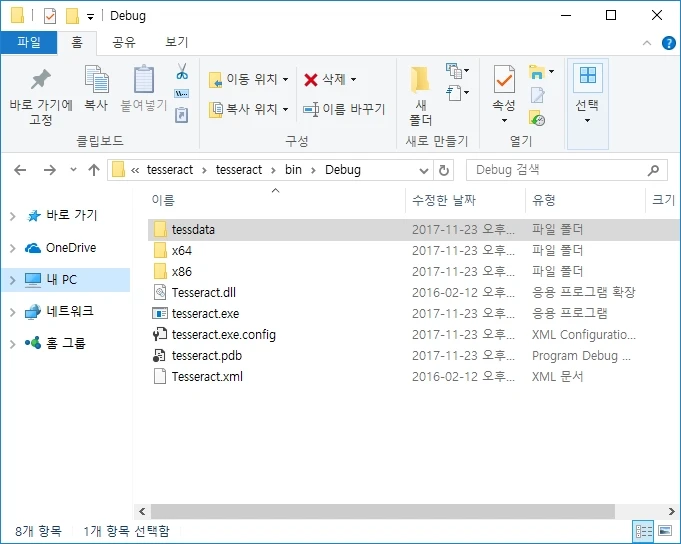
1강에서 설치한 Tesseract 언어 데이터 파일을 프로젝트/bin/Debug에 저장합니다.
Tesseract 설치하기: 1강 바로가기
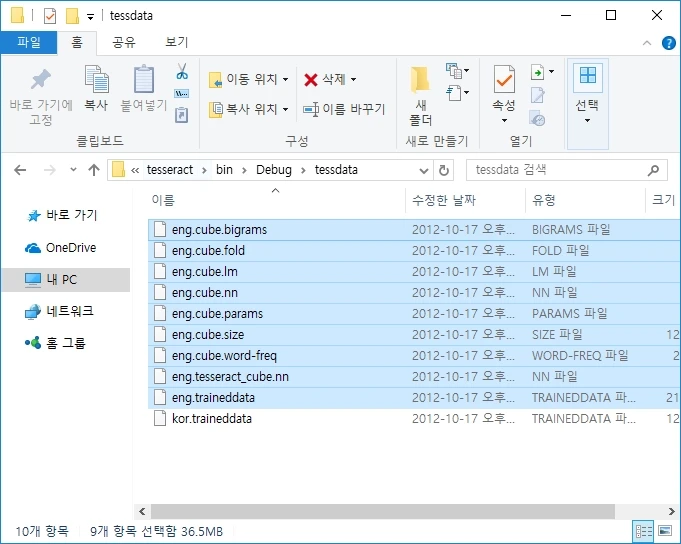
tessdata 폴더에 위와 같은 eng.* 파일이 정상적으로 저장되어있는지 확인합니다.
프로젝트 구성
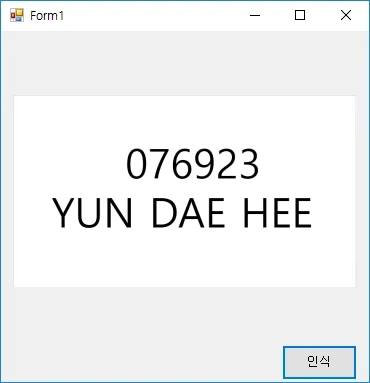
Form창에 위와 같이 pictureBox와 button을 배치합니다. pictureBox에 이미지를 등록합니다.
전체 코드
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using Tesseract;
namespace tesseract
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
Bitmap img = new Bitmap(pictureBox1.Image);
var ocr = new TesseractEngine("./tessdata", "eng", EngineMode.TesseractAndCube);
var texts = ocr.Process(img);
MessageBox.Show(texts.GetText());
}
}
}세부 코드
using Tesseract;namespace에 Tesseract를 사용할 수 있도록 선언합니다.
Bitmap img = new Bitmap(pictureBox1.Image);pictureBox1의 이미지를 Bitmap으로 변환하여 img 변수에 저장합니다.
var ocr = new TesseractEngine("./tessdata", "eng", EngineMode.TesseractAndCube);ocr 변수에 TesseractEngine()을 이용하여 언어 데이터 파일을 사용하여 판독합니다.
TesseractEngine(언어 데이터 파일 경로, 언어, 엔진모드)입니다. 영어의 경우 eng입니다.
-
EngineMode.*EngineMode.Default: 기본값으로 판독EngineMode.CubeOnly: 큐브 방식으로 정확도는 높아지지만, 속도가 느림EngineMode.TesseractOnly: Tesseract 방식만 실행하며, 속도가 가장 빠름EngineMode.TesseractAndCube: 큐브와 Tesseract 방식의 결합, 가장 높은 정확도
var texts = ocr.Process(img);
MessageBox.Show(texts.GetText());texts에 ocr에서 셋팅된 방법으로 img를 이용해 판독할 문자들을 저장합니다.
texts.GetText()를 이용하여 string형태로 불러올 수 있습니다.
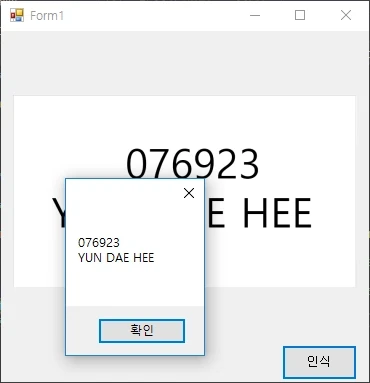
출력 결과
공유하기
 Kakao
Kakao
 Naver
Twitter
LinkedIn
Facebook
Naver
Twitter
LinkedIn
Facebook
댓글 남기기