Python Pytorch 강좌 : 제 11강 - 데이터 세트 분리(Data Set Split)
데이터 세트 분리(Data Set Split)
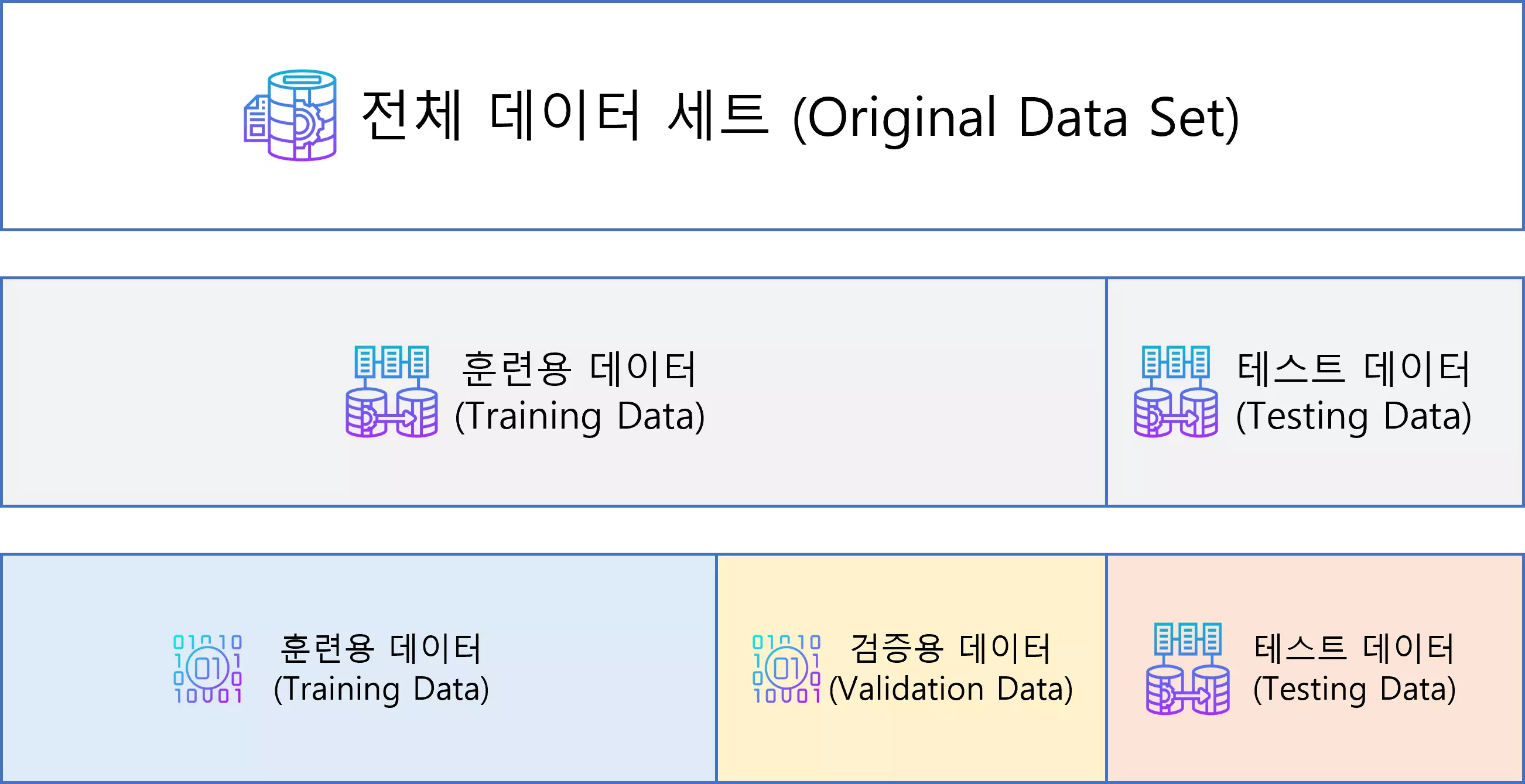
인공 신경망(Neural Network)에 사용되는 데이터 세트는 크게 세 가지가 사용됩니다.
전체 데이터 세트(Original Data Set)을 세 가지 목적으로 분류하여 사용됩니다.
전체 데이터 세트는 훈련용 데이터(Training Data), 검증용 데이터(Validation Data), 테스트 데이터(Testing Data)로 분류됩니다.
훈련용 데이터(Training Data)
훈련용 데이터(Training Data)는 모델(Model)을 학습하는 데 사용되는 데이터 세트입니다.
지금까지는 전체 데이터 세트(Original Data Set)를 그대로 사용하여 학습시키고 임의의 값을 입력하여 검증하거나 테스트를 진행하였습니다.
하지만, 이러한 방법은 모델을 평가하는데 적합한 방법이 아닙니다.
그러므로, 목적에 따라 데이터 세트를 분리하여 검증과 테스트를 진행합니다.
검증용 데이터(Validation Data)
검증용 데이터(Validation Data)는 학습이 완료된 모델을 검증(Validation)하기 위해 사용되는 데이터 세트입니다.
서로 다른 모델을 사용했을 때 성능 비교를 하기 위해 사용되는 데이터 세트입니다.
또한 모델의 계층(Layer)이 다르거나 에폭(Epoch)이나 학습률(Learning Rate)과 같은 하이퍼 파라미터(HyperParameter)에 따라 학습 결과가 달라질 수 있는 것을 확인했습니다.
이러한 계층이나 하이퍼 파라미터의 차이 등으로 인한 성능을 비교하기 위해 사용됩니다.
테스트 데이터(Testing Data)
테스트 데이터(Testing Data)는 검증용 데이터(Validation Data)를 통해 결정된 성능이 가장 우수한 모델을 최종 테스트 하기 위한 목적으로 사용되는 데이터 세트입니다.
앞선 검증용 데이터에 선택된 모델은 검증용 데이터에 과대적합(Overfitting)된 모델이거나, 검증용 데이터가 해당 모델에 적합한 형태의 데이터만 모여있을 수 있습니다.
그러므로, 기존 과정에서 평가해보지 않은 새로운 데이터인 테스트 데이터로 최종 모델 성능 평가를 진행하게 됩니다.
즉, 훈련용 데이터(Training Data)는 모델 학습을 위한 데이터 집합, 검증용 데이터(Validation Data)는 모델 선정을 위한 데이터 집합, 테스트 데이터(Testing Data)는 최종 모델의 성능을 평가하기 위한 데이터 집합으로 볼 수 있습니다.
전체 데이터 세트(Original Data Set)에서 각각의 데이터 집합으로 분리하는 비율은 일반적으로 6:2:2를 사용하지만, 현재 가지고 있는 데이터 세트의 크기에 따라 조정해서 사용합니다.
메인 코드
import torch
import pandas as pd
from torch import nn
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
class CustomDataset(Dataset):
def __init__(self, file_path):
df = pd.read_csv(file_path)
self.x = df.iloc[:, 0].values
self.y = df.iloc[:, 1].values
self.length = len(df)
def __getitem__(self, index):
x = torch.FloatTensor([self.x[index] ** 2, self.x[index]])
y = torch.FloatTensor([self.y[index]])
return x, y
def __len__(self):
return self.length
class CustomModel(nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
self.layer = nn.Linear(2, 1)
def forward(self, x):
x = self.layer(x)
return x
dataset = CustomDataset("./dataset.csv")
dataset_size = len(dataset)
train_size = int(dataset_size * 0.8)
validation_size = int(dataset_size * 0.1)
test_size = dataset_size - train_size - validation_size
train_dataset, validation_dataset, test_dataset = random_split(dataset, [train_size, validation_size, test_size])
print(f"Training Data Size : {len(train_dataset)}")
print(f"Validation Data Size : {len(validation_dataset)}")
print(f"Testing Data Size : {len(test_dataset)}")
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True, drop_last=True)
validation_dataloader = DataLoader(validation_dataset, batch_size=4, shuffle=True, drop_last=True)
test_dataloader = DataLoader(test_dataset, batch_size=4, shuffle=True, drop_last=True)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CustomModel().to(device)
criterion = nn.MSELoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.0001)
for epoch in range(10000):
cost = 0.0
for x, y in train_dataloader:
x = x.to(device)
y = y.to(device)
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cost += loss
cost = cost / len(train_dataloader)
with torch.no_grad():
model.eval()
for x, y in validation_dataloader:
x = x.to(device)
y = y.to(device)
outputs = model(x)
print(f"X : {x}")
print(f"Y : {y}")
print(f"Outputs : {outputs}")
print("--------------------")- 결과
- Training Data Size : 160
Validation Data Size : 20
Testing Data Size : 20
X : tensor([[70.5600, 8.4000],
[ 4.8400, -2.2000],
[64.0000, 8.0000],
[53.2900, 7.3000]], device=’cuda:0’)
Y : tensor([[204.4700],
[ 19.0800],
[184.8700],
[152.8700]], device=’cuda:0’)
Outputs : tensor([[204.9823],
[ 19.2306],
[185.3219],
[153.3037]], device=’cuda:0’)
——————–
{이하 생략}
세부 코드
from torch.utils.data import Dataset, DataLoader, random_split데이터 세트를 분리하기 위해 torch.utils.data에서 random_split 함수를 포함시킵니다.
dataset = CustomDataset("./dataset.csv")
dataset_size = len(dataset)
train_size = int(dataset_size * 0.8)
validation_size = int(dataset_size * 0.1)
test_size = dataset_size - train_size - validation_size전체 데이터 세트(dataset)에서 훈련용 데이터(Training Data), 검증용 데이터(Validation Data), 테스트 데이터(Testing Data)를 8:1:1 비율로 분리하도록 하겠습니다.
각각 분리한 데이터 세트들의 합은 전체 데이터 세트의 크기와 동일해야 하므로, 정수형(int)으로 변환하여 계산합니다.
훈련용 데이터 크기(train_size)는 약 80% 비율, 검증용 데이터 크기(validation_size)는 약 10% 비율, 테스트 데이터 크기(test_size)는 나머지 크기(약 10%)로 할당합니다.
train_dataset, validation_dataset, test_dataset = random_split(dataset, [train_size, validation_size, test_size])
print(f"Training Data Size : {len(train_dataset)}")
print(f"Validation Data Size : {len(validation_dataset)}")
print(f"Testing Data Size : {len(test_dataset)}")데이터 세트 분리(random_split) 함수를 사용하여 데이터 세트를 분리합니다.
split_dataset = torch.utils.data.random_split(dataset, [*size])은 전체 데이터 세트(dataset)에 분할 크기(*size)로 나눠진 분리된 데이터 세트(split_dataset)를 반환합니다.
분할 크기(*size)의 길이와 동일하게 분리된 데이터 세트(split_dataset)가 생성됩니다.
분리된 데이터 세트는 무작위로 분할되어 반환됩니다.
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True, drop_last=True)
validation_dataset = DataLoader(train_dataset, batch_size=4, shuffle=True, drop_last=True)
test_dataset = DataLoader(train_dataset, batch_size=4, shuffle=True, drop_last=True)모든 데이터 세트에 데이터 로더(DataLoader)를 적용합니다.
데이터 로더에 사용되는 매개 변수는 동일하게 설정하지 않아도 됩니다.
for x, y in train_dataloader:
...모델 학습에서는 학습용 데이터 세트를 사용하여 학습을 진행합니다.
with torch.no_grad():
model.eval()
for x, y in validation_dataloader:
x = x.to(device)
y = y.to(device)
outputs = model(x)
print(f"X : {x}")
print(f"Y : {y}")
print(f"Outputs : {outputs}")
print("--------------------")모델 검증 과정에서는 검증용 데이터(validation_dataloader)로 검증을 진행합니다.
여러 모델들로 검증을 진행하며, 이 결과에서 우수한 성능을 내는 모델을 결정합니다.
모델이 결정되면 최종 평가를 위해 테스트 데이터(test_dataloader)로 테스트를 진행합니다.
공유하기
 Kakao
Kakao
 Naver
Twitter
LinkedIn
Facebook
Naver
Twitter
LinkedIn
Facebook
댓글 남기기