Python OpenCV 강좌 : 제 43강 - K-최근접 이웃 알고리즘
K-최근접 이웃(K-Nearest Neighbor Algorithm)
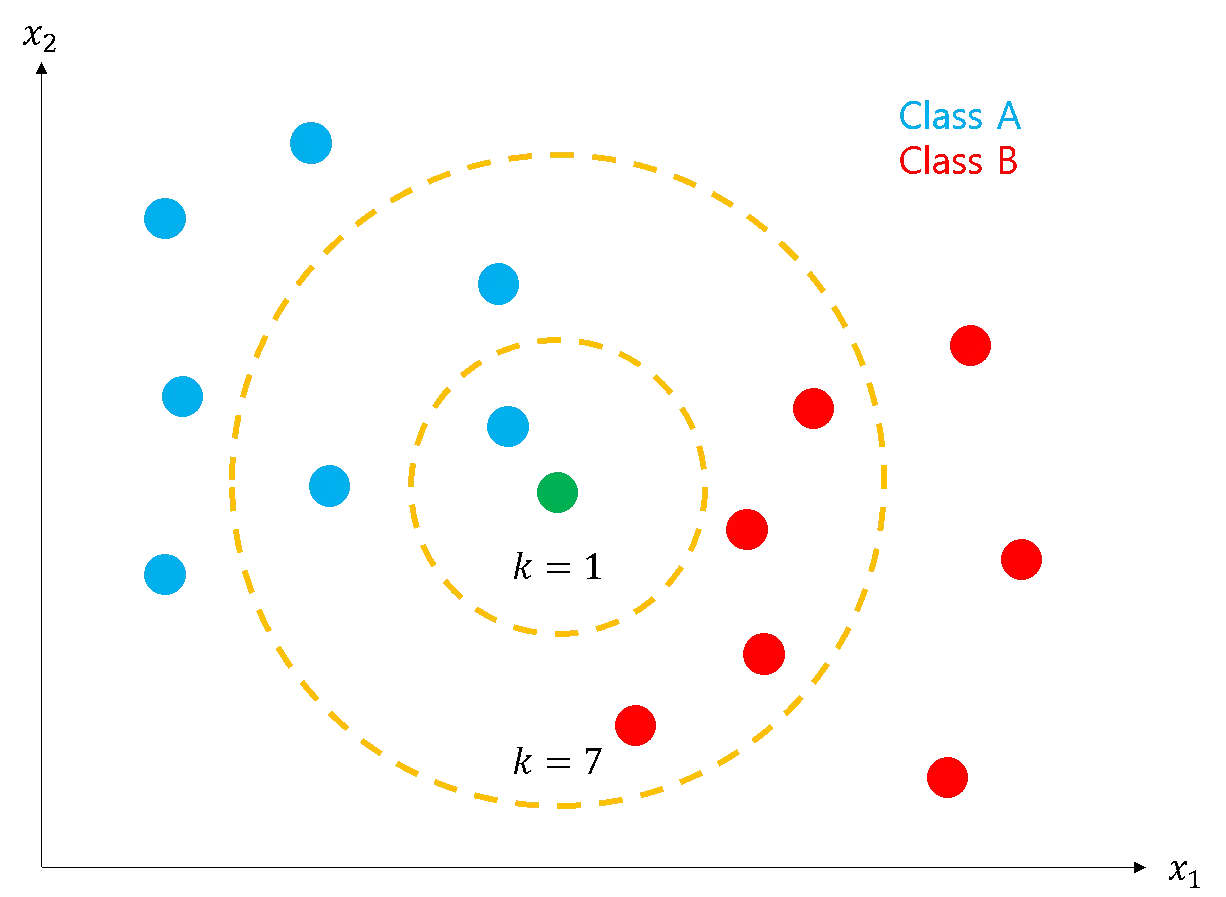
K-최근접 이웃 알고리즘(K-Nearest Neighbor Algorithm, KNN)은 지도 학습에 사용할 수 있는 가장 간단한 분류 알고리즘 중 하나로, 회귀 분석이나 분류에서 사용되는 알고리즘입니다.
이 알고리즘은 새로운 데이터가 입력되었을 때 기존의 데이터와 가장 가까운 k개 데이터의 정보로 새로운 데이터를 예측하는 방법입니다.
즉, 새로운 데이터 주변에 분포해 있는 이웃 데이터의 성질을 토대로 판단합니다.
위 그림에는 파란색, 초록색, 빨간색의 원이 존재합니다.
이 그림에는 파란색과 빨간색의 두 그룹이 존재합니다. 이 그룹군들을 클래스(Class)라고 부르며, N차원 특징 공간(Feature Space)에 표현될 수 있습니다.
이 특징 공간에 새로운 데이터인 초록색 원이 주어졌을 때, K-최근접 이웃 알고리즘은 어느 클래스에 분류될지를 판단하게 됩니다.
이때 최근접 이웃(Nearest Neighbor) 방식을 사용하며, 가장 가까운 지점간의 거리가 가장 짧은 클래스로 분류됩니다.
만약, K=1이라면 초록색 원에서 가장 가까운 1개의 원은 파란색 원이 되어 파란색 클래스가 되고, K=7이라면 가장 가까운 원은 파란색 원 3개, 빨간색 원 4개로 초록색 원은 빨간색 클래스가 됩니다.
즉, K-최근접 이웃 알고리즘은 새로운 데이터가 입력되었을 때 가장 가까운 K개를 비교하여 가장 거리가 가까운 개수가 많은 클래스로 분류됩니다.
여기서 주의해야할 사항으로는 K가 짝수라면 근접한 클래스의 개수가 동점이 발생할 수 있습니다.
K-최근접 이웃 알고리즘은 동점이라도 거리가 더 가까이에 있는 클래스에 가중치를 부여하지 않으므로, 가능한 K를 홀수로 사용하는 것이 좋습니다.
메인 코드
import cv2
import numpy as np
def loadTrainData(image_path, label_path):
with open(image_path, "rb") as image_data:
images = np.frombuffer(image_data.read(), dtype=np.uint8, offset=16)
with open(label_path, "rb") as label_data:
labels = np.frombuffer(label_data.read(), dtype=np.uint8, offset=8)
return images.reshape(-1, 784), labels
train_x, train_y = loadTrainData(
"./fashion-mnist/train-images-idx3-ubyte",
"./fashion-mnist/train-labels-idx1-ubyte"
)
test_x, test_y = loadTrainData(
"./fashion-mnist/t10k-images-idx3-ubyte",
"./fashion-mnist/t10k-labels-idx1-ubyte"
)
label_dict = {
0: "T-shirt/top",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle boot",
}
knn = cv2.ml.KNearest_create()
retval = knn.train(train_x.astype(np.float32), cv2.ml.ROW_SAMPLE, train_y.astype(np.int32))
count = 500
retval, results, neighborResponses, dist = knn.findNearest(
test_x[:count].astype(np.float32), k=7
)
matches = results.astype(np.uint8) == test_y[:count][:, None]
print(np.count_nonzero(matches) / count * 100)
for idx, result in enumerate(results):
print("Index : {}".format(idx))
print("예측값 : {}".format(label_dict[int(result)]))
print("실제값 : {}".format(label_dict[test_y[idx]]))
cv2.imshow("images", test_x[idx].reshape(28, 28, 1))
cv2.waitKey()세부 코드
Fashion-MNIST
def loadTrainData(image_path, label_path):
with open(image_path, "rb") as image_data:
images = np.frombuffer(image_data.read(), dtype=np.uint8, offset=16)
with open(label_path, "rb") as label_data:
labels = np.frombuffer(label_data.read(), dtype=np.uint8, offset=8)
return images.reshape(-1, 784), labels
train_x, train_y = loadTrainData(
"./fashion-mnist/train-images-idx3-ubyte",
"./fashion-mnist/train-labels-idx1-ubyte"
)
test_x, test_y = loadTrainData(
"./fashion-mnist/t10k-images-idx3-ubyte",
"./fashion-mnist/t10k-labels-idx1-ubyte"
)Fashion-MNIST은 기존의 MNIST 데이터 세트를 대신해 사용할 수 있게 제공되는 패션 데이터 세트입니다.
Fashion-MNIST 데이터 세트는 60,000 개의 훈련 데이터와 10,000개의 테스트 데이터를 제공합니다.
이미지 데이터는 28 × 28 크기의 회색조 이미지 데이터를 제공하며, 라벨 데이터는 10개의 클래스가 라벨링 되어 있습니다.
Fashion-MNIST은 Zalando Research Gitub에서 다운로드 할 수 있습니다.
또는 다음 링크에서도 다운로드 할 수 있습니다.
Fashion-MNIST 다운로드: 다운로드
데이터 세트는 다음과 같은 형태를 가집니다.
| 파일명 | 내용 | 개수 | 오프셋 바이트 |
|---|---|---|---|
| train-images-idx3-ubyte | 훈련 이미지 | 60,000 | 16 |
| train-labels-idx1-ubyte | 훈련 라벨 | 60,000 | 8 |
| t10k-images-idx3-ubyte | 테스트 이미지 | 10,000 | 16 |
| t10k-labels-idx1-ubyte | 테스트 라벨 | 10,000 | 8 |
오프셋 바이트(Offset Byte)는 파일 시그니처의 바이트를 의미합니다.
이미지는 16 바이트를 오프셋하고, 라벨은 8 바이트를 오프셋합니다.
이미지에 포함된 파일 시그니처는 각각 4 바이트씩 파일 매직 넘버, 이미지 개수, 이미지 행의 개수, 이미지 열의 개수를 포함하고 있으며, 라벨에 포함된 파일 시그니처는 파일 매직 넘버, 라벨 개수를 포함하고 있습니다.
데이터는 open() 함수를 rb 모드로 사용해 이진파일로 읽습니다.
np.frombuffer() 함수로 버퍼를 읽어 들입니다. dtype 매개변수의 인수는 np.uint8을 사용합니다.
offset 매개변수에 할당되는 값은 오프셋 바이트를 입력해야 하므로 이미지에 16, 라벨에 8을 입력합니다.
label_dict = {
0: "T-shirt/top",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle boot",
}라벨 데이터는 숫자로 입력되어 있습니다. 라벨 번호에 대한 의미는 다음과 같은 형태를 가집니다.
사전(Dictionary)을 활용하여 간단하게 매핑을 진행합니다.
| 라벨 | 의미 | 라벨 | 의미 |
|---|---|---|---|
| 0 | T-Shirt/top | 5 | Sandal |
| 1 | Trouser | 6 | Shirt |
| 2 | Pullover | 7 | Sneaker |
| 3 | Dress | 8 | Bag |
| 4 | Coat | 9 | Ankle boot |
K-최근접 이웃 알고리즘 훈련
knn = cv2.ml.KNearest_create()
retval = knn.train(train_x.astype(np.float32), cv2.ml.ROW_SAMPLE, train_y.astype(np.int32))K-최근접 이웃 알고리즘 클래스(cv2.ml.KNearest_create)로 knn 인스턴스를 생성합니다.
인스턴스가 생성되었다면, K-최근접 이웃 알고리즘 훈련 메서드(knn.train)로 훈련을 진행합니다.
retval = knn.train(samples, layout, responses)은 훈련 데이터(samples)에서 어떠한 배치 형태(layout)로 구성되어 있는지 확인해 라벨(responses)과 매핑합니다.
훈련 데이터(samples)는 CV_32F(float) 형식을 사용하며, 라벨(responses)은 CV_32F(flaot) 형식 또는 CV_32S(int) 형식을 사용합니다.
배치 형태(layout)는 두 가지의 플래그만 존재합니다.
훈련 데이터의 데이터가 행(ROW_SAMPLE)으로 구성되어 있는지, 열(COL_SAMPLE)로 구
성되어 있는지 설정합니다.
반환되는 결과(retval)는 학습이 정상적으로 진행되었으면 참 값을 반환하고, 학습에 실패했다면 거짓 값을 반환합니다.
K-최근접 이웃 알고리즘 예측
count = 500
retval, results, neighborResponses, dist = knn.findNearest(
test_x[:count].astype(np.float32), k=7
)K-최근접 이웃 알고리즘 이웃 예측 메서드(knn.findNearest)로 훈련 모델에 대한 예측(predict)을 진행합니다.
retval, results, neighborResponses, dist = knn.findNearest(samples, k)는 테스트 데이터(samples)에 대해 최근접 이웃 개수(k)에 대한 예측값을 반환합니다.
반환값(retval)은 첫 번째 테스트 데이터에 대한 예측 결과를 반환하며, 결괏값(results)은 테스트 데이터에 대한 모든 예측 결과를 반환합니다.
결괏값(results)은 (N, 1)의 크기를 가지며 (CV_32F) 형식으로 반환됩니다.
이웃 응답값(neighborResponses)과 거리(dist)는 예측 결과를 분석하기 위해 사용된 최근접 이웃의 클래스 정보와 거리(L2-Norm)를 반환합니다.
이웃 응답값(neighborResponses)과 거리(dist)는 (N, k) 크기를 가지며 CV_32F 형식으로 반환됩니다.
테스트 데이터는 간략하게 500개만 사용해 평가합니다.
데이터 타입의 기본값을 np.uint8로 사용했으므로 예측 메서드의 테스트 데이터 형식 을 np.float32로 변경합니다.
예측이 완료된 후 비교 연산을 진행할 때, test_y를 전치 행렬로 변경해야하므로, test_y에 [:, None] 구문을 추가합니다.
[:, None] 구문은 배열에 열 벡터를 생성해 test_y를 전치 행렬로 변경할 수 있습니다.
for idx, result in enumerate(results):
print("Index : {}".format(idx))
print("예측값 : {}".format(label_dict[int(result)]))
print("실제값 : {}".format(label_dict[test_y[idx]]))
cv2.imshow("images", test_x[idx].reshape(28, 28, 1))
cv2.waitKey()결괏값(results)을 반복하여 예측값과 실제값을 비교합니다.
기존에 선언한 label_dict에 결과를 입력하여 확인합니다.
출력 결과




87.4
Index : 0
예측값 : Ankle boot
실제값 : Ankle boot
Index : 1
예측값 : Pullover
실제값 : Pullover
...공유하기
 Kakao
Kakao
 Naver
Twitter
LinkedIn
Facebook
Naver
Twitter
LinkedIn
Facebook
댓글 남기기